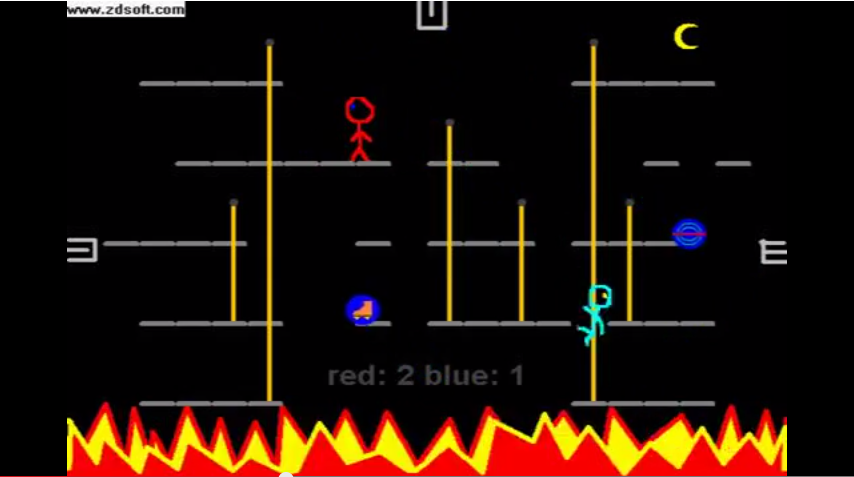
Ever since it was announced I've been very excited to try out the new ML library in Unity, but I haven't had time until Game Jam Island. This past week I've been setting up and doing some experiments. I wanted to see if it can be used in a real-world scenario for game development, so I set about trying to create some bots for Frog Smashers.
Frog Smashers is a simple local multiplayer versus game (made during the first Game Jam Island) where Frogs try to hit each other out the screen with baseball bats. It's some sort of a mixture between Samurai Gunn and Ninendo's Smash series. It's a good choice because of its familiar mechanics, and small enough of a project for it to be malleable, and simple enough that I'd expect good results from machine learnt bots.
If you want more information on how to setup Machine Learning in Unity or how it works, I recommending starting here.
The first step was to change all game logic to run in FixedUpdate, so the game can run at the massive timescales required to train within a reasonable amount of time. This might be a problem for larger/different games and I'm not quite sure how to address it, Unity would need an engine-level feature for faking Time.deltatime. Luckily the project was small enough that this wasn't a big issue.
I used a vectorised observation for each frog, consisting of position, velocity, and some state information (e.g. are they currently knocked/attacking). I've found with ML that keeping the observations as small as possible gives better results - I've seen some people try a strategy of spamming as much information as possible and trusting ML to figure out what's important, but every time I've tried that, training just seemed way slower, without improving on a simplified model even at high amounts of steps. I tried two strategies, the first would simply track the agent's own frog and the closest enemy frog, the second has an array of observations corresponding to 4 frogs. I expected the 4 frog observation model to eventually perform better, but it did not discernably do so even at high (~5 million) steps. Given that the closest frog training model also scales better to any amount of frogs, that's the one that I'd recommend (the linked FrogAgent is the 4 frog model, but switching between the two is trivial).
This model would require retraining for each level, as the bots will learn the layout of the level implicitly. If I were to try make it generalised, I would make a camera that can only see the level layout (and perhaps frogs themselves) with level switching and an academy reset, but I felt that was beyond the scope of what I was trying to do. Still it'd be interesting to see if a camera observation of the level makes them learn the layout more effectively.
The first iteration had a continuous action vector setup, (e.g. input.left == act[0] >1) but switching over to a discrete action vector setup made a HUGE difference. The second iteration had a discrete action space size of 128 (e.g. 8 bits, one corresponding to each bool in InputState), and I'd bitmask to find whether each button was pressed. This still had a fair amount of redundancy, in that in this game pressing left & right together is the same as pressing neither, and frogs can't attack and use tongue at the same time. Removing those redundancies and decreasing the action space size to 57 (9 directions * 3 attack states * 2 jump or not) made another near order-of-magnitude difference in training time.
Tuning the reward function takes some time and just a bunch of guesswork. I recommend setting the game window's size larger than the default and making keyboard controls to slow down or speed up timescale, so you can keep an eye on what your agents are doing. For the most part, my frogs (like most frogs) only care about hitting each other with baseball bats. There are some penalties applied for missing attacks, to prevent them from continually spamming the attacks, and a minor conservation of energy penalty for jumping. Adding a small 'hint' reward for closing the distance to the nearest enemy also speeds up the first steps of training significantly. Adding a reward for knocking a frog out of the level (rather than just hitting him at all), did not make a big discernible difference in output, though I suspect at ~10 million steps of training you might see them starting to strategise a bit more.
The agents do still behave quite botlike, and typically rely on their advanced reaction speed to win. Still, at ~3 million steps they play on a reasonably advanced level and will likely be able to beat most humans. One of the challenges would be to get them to play a bit more human and to slow down their reaction speeds. Increasing the amount of timesteps between decisions will likely help, I'd also be interested in seeing what happens if you buffer input for about 0.15 seconds before executing, so that they have to play with more human reaction speeds. I'm also not sure how you would go about scaling bot difficulty with a single brain, beyond slowing down their reaction speeds.
I'm confident that with more tweaking and training I could get even better results that I did currently, however for a day's work, which included reworking the project to run in FixedUpdate, setting up training parameters and training overnight, these results are already very encouraging and I'm really looking forward to doing some more ML experiments and seeing what people come up with as the tools mature.
You can tweet me at @rrza with any questions/comments, thanks for reading! Frogs.
Little over a year ago I thought it'd be a good idea to quit my stable, 40-hour-a-week job to make by childhood wish come true and start making violent video games for a living. The past year has been a rollercoster with lots of successes, failures and lessons learnt. I've been doing some stocktaking, trying to figure out what I've learnt and I've come up with a list of things that I wish I knew two years ago, before I started on all this. I hope this can help anyone else starting out on this silly venture of making games...
1. Don’t fall in love with your game
When I was starting out on trying to become an indie developer, I’d made one or two small projects, and I asked some of my friends to play them to test and get some feedback. I got annoyed with my friends when they weren’t that interested in playing my games. But really, it wasn’t their fault, it was my fault for making shitty games. The first thing to take away here is that you shouldn’t be making shitty games. The second thing is that is is actually quite hard to know when the game your are working on is shitty. I thought my early games were pretty cool, looking back now, I am embarrassed at how bad they were.
Stick Duel is still fucking legit, tho
When you’ve been working on a game for a certain amount of time, it’s easy to not see any of its faults and start thinking it’s the greatest game ever. This is a trap, this is what makes you not be able to throw it away, start anew or iterate quickly. What makes this harder is that very few people are willing to admit that your game is crap, so you have to pick up on cues. I’ve since resorted to the following trick: I’ll ask someone to play my game and I’ll do the usual over-the-shoulder peering to see how they experience the first few minutes. Then I’ll leave the room for some reason. If I come back in a few minutes and the person is still playing, I’ll assume they like the game. If not, they obviously have terrible taste in games and I’ll disregard any feedback they gave me. Dicks.
2. Get feedback early, get feedback often
The timing of when you should start asking for feedback can be tricky to get right. The game must be playable, obviously, with some juice added where it’s important and some effort made to explain the mechanics in-game. But once the bare bones are there and the core mechanics are exposed and it isn’t just falling over at random, you should start trying to get some people to play your game. Join a few forums, become involved in communities and post your game for others to play. Unity webplayer is excellent in this regard, as it lets people play your game as easily as possible.
What works even better is to have people play it while you are watching in person. However, it is crucial that you do not interrupt or give any clues as to how your game works, or you will not learn what is and what isn’t being explained in your game and taint their first experience, meaning you will not learn what you need to.
Try to also not have too many people play the same version of your game - it is always important to gauge the first impression your game makes. Having people see your game for the first time in each stage of feedback is important so you can gauge if that improvement you made to the tutorial is panning out.
3. Tech doesn’t really matter
Stop worrying about whether you are using the right tools. Get an engine you are comfortable with, and go with it. If you are required to use a different engine at some stage you will be able to translate over your skills in a short amount of time. If you feel limited by the tech you are using, you are probably not being creative enough.
Black Annex - made in Q-Basic - the first language I learnt.
In my personal opinion, everyone starting out should be using either Gamemaker or Unity, probably Unity these days, but it really doesn’t matter. Also, use an engine, unless you are masochistic or enjoy programming more than creating games - although lots of excellent games are made with small teams and their own engines.
4. Don’t work in secret
Early access and open development practices are becoming more and more popular and with good reason - it’s simply a much better methodology for developing games. Don’t be concerned that people might want to ‘steal your ideas’, because:
5. Ideas are overrated
I’m not sure whether I’ve been successfully blocking these people out or whether this has become less prevalent but for the love of god please stop thinking you have an amazing idea. You almost certainly don’t have an idea that a hundred other people haven’t already had, and even if you did, the idea is worth far less than the execution. Take Narbacular Drop, for example. An excellent, revolutionary idea that won GOTY the world over, but only when it was executed to perfection as Portal. Of course, we all love our own ideas, and those ideas are what get us excited and why we work in game development, but it only has value once it is realized.
6. If you wanna make games, make games (not excuses)
I’ve heard a few people say that they are interested in making games, when I ask to see what they’ve made, they’ll usually offer an excuse such as they’re still forming a team, or they are still reading up, or that it’s hard and they don’t have time, or whatever. I don’t care. I’d already stopped paying attention. This doesn’t just apply to games, but if you want to do something, then do it. All the information and tools you could ever need is available for free on the internet. Yes, your first few games will be embarrassingly bad, but that goes for everybody. The only way to get to the stage of making less shitty games is by making those shitty games first. You don’t need a team and if you are new to making games you should not be working in a team, anyway.
7. Juice is king
A game is not a game until it has camera shake. I don’t care whether you are making a text based depression simulator, add some god damn camera shake. Hearthstone is a card game and it’s jucier than most FPS’s, which is probably the single biggest reason for its success. Peggle is a game with nothing BUT juice, and look how well that has done. When in doubt, particle effects and camera shake.
Particles! Explosions! (not pictured: camera shake)
8. Find some cool bros to work with
After you’ve built up some experience, maybe did a jam or two by yourself, it’s definitely worthwhile to find a few people to team up with and do a group project. I'm lucky to be working with some ridiculously talented and driven people and the rate at which I've learnt has skyrocketed. There is also great value in being able to work with a group in person rather than remotely, as ideas can be bounced around far faster than over email or skype.
9. Learn to teach
The art of conveyance is a cornerstone of game design. It is critical to learn how to teach people your game while they are playing, without them realizing that they are taking lessons. Using text to instruct a player anything is a mistake, most people will just blindly ignore text on the screen.
10. Gamejams are great
Something I'm guilty of is not participating in enough jams. Jams are great for trying out that weird idea you aren't certain of, getting something 'finished' after a weekend and getting easy feedback from other participants. It's also great for building up a portfolio, which is by far your most useful asset to get hired.
11. Making Games != Playing Games
Game development is some of the hardest (desk bound) work you can do. There is a very long road between seeing a picture of the game you want to play and realizing it. On top of that, competition in the indie space is hectic and getting tougher every day. Making an average, or even just a good game isn't enough any more, you have to stand out above the crowd and that takes work. If you want to succeed professionally, while still making an interesting game to your own vision, you have to go the extra mile and be prepared to give up sleep/free time/sanity to accomplish your goal. Whether it's worth it or not is up to you - I know it's certainly been the case for me!
A lot has been said about Greenlight recently, most of it very negative, and with Broforce being greenlit, I wanted to share some of my experiences and thoughts to perhaps present a more balanced picture of the challenges a developer faces while trying to get greenlit.
For those that don’t know, Broforce is a 2D action platformer where players take on the role of every action hero from the 80s and 90s to defeat satanic terrorists that you can play for free right now.
The first part of this article is essentially a post-mortem of our successful Greenlight campaign. I hope that my experiences with the system can lend some insight to those planning their Greenlight campaigns.
In the second part I try to counter some of the criticisms that have been leveled at Greenlight. It is not my belief that everyone who dislikes Greenlight does so because they adhere to these criticisms, but some developers have made these particular claims without any public debate from the game development community as to their validity (that I am aware of). I hope my perspective can start a more constructive discussion about Steam’s Greenlight process.
Lastly I make an argument for why Greenlight can be a powerful tool within a game developers arsenal, rather than an obstacle in their path.
This article makes certain assumptions. One assumption is that Steam heavily curating their marketplace is a good thing, and that a more open marketplace, like the AppStore, would make Steam less effective as a distribution/marketing platform. A debate about whether Steam should be more open in the future, and how it should achieve that in order to benefit everyone, is not within the scope of this article. I also don’t think Greenlight is perfect, but in order to not derail the article we’re not going to go into our ideas for how to improve the service. You can view some of Gabe Newell’s ideas for the future here.
Broforce’s summit of Mount Greenlight
I joined Free Lives at about the same time Greenlight launched. Broforce was put onto Greenlight in the first few days of the system going public. At that stage Broforce had nowhere near the level of polish it has today: most of the artwork was still from the original Ludum Dare entry, enemies were very limited, bro's did not even have their own special abilities. We got a little bit of attention then, mostly thanks to Greenlight itself being new & novel and attracting a lot of visitors. We also gained a couple of fans who have stayed loyal throughout, but for the most part the internet forgot about Broforce.
Our core strategy for Greenlight was simply to maintain a version of our game at all times that anyone can play, and that prompts you to vote for it on Greenlight. We're not a well known studio, we don't have any powerful journalist friends, we simply have a game that (we think) is fun to play and we've let people play it.
One of the interesting things to observe from our time on Greenlight is how well votes corresponded to the quality of the game. At the start of our campaign the game was quite rough and we didn't get very many daily votes:
We had a spike or two where we got some early articles/youtube videos (including two really kickass ones by EatMyDiction), but our average daily vote always quickly plummeted. In February we started attacking greenlight in earnest: We hired a person to manage marketing and press relations and started launching more frequent, high quality updates to Broforce and you can clearly see our average daily rate improve.
We were sitting on about 20-50 votes a day as baseline before February. From February to April we were seldom getting below 50, and from April (after a Cyprien Squeezie video with 700,000 views) until late June we were seldom dropping below 100.
In May we launched one of the biggest updates for the brototype which included much better enemy variation and a boss. We also launched a trailer (the one at the start of this article) that reflected the updated quality of the game, and which had a request for people to vote for the game on Greenlight. I think it is critical that the request for Greenlight voting was in the video itself (not in the description) so that people still see it when watching the trailer as embedded video, and the request should be as succinct as possible and at the end of the video. We also intentionally put the line "Link in description" in the video itself so that embedders were forced to link our greenlight campaign. This is what our greenlight graph looks like from then until now:
As the quality of the game improved and people spread it to friends our fanbase increased. In the month of May Broforce got over 100,000 unique players, and the little bit of buzz around our game was enough for it to generate a constant stream of attention from youtube channels.
On June 25 we were at about #40 on Greenlight. We released an updated trailer for Broforce that day, which received coverage in most major American indie game press websites, as well two Markiplier videos. From that day onwards we didn’t receive fewer than 350 votes in a day and climbed rapidly through the ranks.
On the 12th July, we were sitting at #16 with 40000 votes. 12 days later, after a Jesse Cox and two Yogscast videos, we got greenlit. At that point we were at #2 with 82000 votes.
All of this seems quite counter to what greenlight detractors typically say: We were not popular to begin with. Our game doesn't have the words "zombie", "craft", "simulator" or "slender" in the title. While we did get a lot of help from various sources, we did not have ties to any publisher or big names in the Indie space with the kind of popularity that could push thousands of voters to Greenlight.
We had no magic bullet with which to conquer Greenlight, instead we worked hard to make an appealing game, we put some effort into making videos of the game that helped it get noticed, and we made it as easy as possible for people to play it and share it (and then asked them nicely to vote for us). We saw early on the impact of Let’s Play videos and tried to ensure that our game would work well under those conditions.
These were very much the sorts of development practices that we would have (hopefully) followed anyway. We found that in the case of Broforce the Greenlight system rewarded us for developing the game openly. And open development in turn ensured that we had a lot of feedback with which to test and improve the game, which fed back into tangible results on Greenlight.
This isn’t necessarily a method that fits all games, but I think that Broforce’s success on Greenlight does contradict some of the more wayward Greenlight criticisms. I’d like to offer some responses to other criticisms that Greenlight receives, with some of our thoughts and conclusions from our campaign:
“Niche” games are a tricky subject. A lot of developers who struggle on Greenlight claim that niche games who do not pander can not get through greenlight, yet 'weird' games like McPixel, Papers Please and Shelter have managed to gather enough attention quite easily. It seems to be that people assume because their game is unpopular it is automatically niche when the game being mediocre is far more often the case. With the amount of games being made, competition in the Indie space is intense and your title needs to stand out somehow. Frankly, being niche is in many cases more likely to be an advantage than a disadvantage.
Criticism Rebuttal #2: Greenlight items should receive more traffic from within Steam.
Greenlight detractors have suggested that it would be preferable if more Steam users were being sent to vote on Greenlight items. I don’t see how this would benefit the system at all, if your game receives more random visitors then so would every other game on Greenlight. I suspect users would fatigue of the greenlight queue very quickly if they were more heavily incentivised to vote (in fact their fatigue with unappealing Greenlight campaigns is certainly the main reason the vote counts aren’t higher).
Broforce received the vast majority of its votes from traffic from outside Steam. There was never a chance that a pixel art 2D platform shooter was going to get a high enough “Yes” vote ratio that random visitors alone would vote the game onto Steam, so we worked at driving traffic onto Greenlight from the start. Some players did discover Broforce via Greenlight, but not a significant number.
A system where the vast majority of votes on Greenlight items come from outside Steam is a far better measure of quality than a system where all or most of the votes came from random Steam users. In a random user “yes/no” voting system there would be no measure of passion, so the games with the broadest possible appeal would be favoured and it would be genuinely bad for niche games.
Criticism Rebuttal #3: Publishers should be allowed to pluck games out of Greenlight and put them on Steam.
Turning Greenlight into a game shopping tool for publishers doesn’t really benefit anyone except publishers. It is safe to assume that even a mediocre game would garner sales on Steam and a predatory publisher may choose to find failing games with desperate developers on the Greenlight queue and push them through onto Steam in return for an unscrupulous cut of the revenue.
If this were to happen the Steam store would lose some of its trust as weaker games that cannot compete on Greenlight are placed on sale. Consumers would have bad experiences playing possibly inferior games. And other developers receive fewer sales as consumers view the Steam store more skeptically.
Steam Greenlight is a system designed to enable better access to self publishing to indie developers, and in Broforce’s case it did just that. There is zero chance that at this stage of development we would have been able to secure a distribution deal on Steam without a publishing arrangement if Greenlight did not exist..
Criticism Rebuttal #4: Good games with plenty of votes aren’t being greenlit.
Chasm is a game that has been touted as being at the centre of Greenlight injustice. Disregarding the fact that the game has actually now been greenlit, I struggle to see how they were suffering an injustice before. The game was still a long ways off from being finished, and Valve had stated explicitly that Greenlight releases were focusing on finished games. I don’t know of any cases where a finished, releasable game has been stuck in the top 10 for longer than a month or two. Even if that is the case, in the old system they would likely have been even more in the dark as it is impossible for Valve to give detailed responses to all applicants, and also impossible for Valve to release every game as it is finished. At the very least, having a good ranking on Greenlight lets you know that your game is under serious consideration for Steam distribution.
Success on Greenlight is actually a damn good barometer for the overall success you can expect from a game. Doing OK on Greenlight initially has allowed us to feel comfortable with allocating all our resources to Broforce's development, and the transparency of Greenlight has given us useful information about the competitiveness of our product in the PC marketplace.
Criticism Rebuttal #5: Some games without a ton of votes get greenlit, therefore the system is broken.
This is only a good thing. It means that if you have a game Valve feel strongly should be on Steam then your game will get on Steam. This is especially good if your game isn’t a game well suited to getting to the top of Greenlight.
Closing thoughts
Deciding which games to publish on Steam, considering the limited bandwidth that a quality service would inevitably have, is undoubtedly a difficult job and I am not insinuating that Greenlight is perfect. I do think it’s the fairest system there is, and Valve have certainly been taking steps to improve it and it will improve in (valve) time.
Greenlight gave us a rallying point to motivate press articles, and even some Youtube videos. It also gave us useful statistics from which to evaluate the effects of our actions and be able to draw comparisons with other campaigns that would have been impossible otherwise. It’s hard to overstate how valuable that has been for us especially because we’re operating from relative isolation in South Africa.
It also allowed players and viewers a soft support option, i.e. clicking “yes” on a button. This provided for us a means to convert fans to supporters. It’s a subtle boundary to cross, but each person who has crossed that boundary will now be slightly more likely to advocate Broforce in the future. That is hugely valuable to us, and perhaps part of the reason why dealing with our players has been such a pleasure throughout Broforce’s development..
Without Greenlight it would have been impossible that Broforce, at this stage of development, would have secured distribution on Steam without publisher assistance. Being able to get that kind of certainty early on as a self-publisher is golden.
As I see it, the biggest difference between our experience on Greenlight and those of detractors has been our attitude. We always saw Greenlight as an opportunity to get on Steam, build a fanbase and gauge interest before release. Most others seem to see it purely as an obstacle to overcome before getting a distribution deal and raking in cash. Making games is hard, doing so professionally and successfully is even harder. If you enter this sphere and want to compete you can’t expect that others will make it easy for you.
(This article was cowritten by Ruan Rothmann and Evan Greenwood)
Damn! So would have thought, we actually won OUYA create! I had expected and hoped we'd do well, and perhaps win one of the subcategories, but considering how we felt after finishing the game, I didn't think we'd win (my personal pick, from only seeing the trailers, was Sky Arena). I'd like to take this opportunity to thank the organisers and judges.
It's kind of a weird position to be in, the day after hand-in we were quite bleak and we had a discussion on what we'd done wrong and what we'd do differently in the future to prevent making these mistakes again. I think a lot of the negative sentiments were amplified due to the jam not ending well for us, with me breaking our repository in the last hours, and some bugs and flow issues not getting sorted out until the last minute. In the post-mortem I talk a lot about having too much ambition for our game but I guess it paid off. Perhaps a side effect of having high ambitions and standards are never quite being happy with your work?
Looking back at the game now, however, I do think it is really strong and impressive for 2 weeks' work. Although it doesn't quite match up to what we'd had in mind at the start, the prototype does demonstrate the potential of our concept quite well, and it is quite fun. We have some time now to fix and improve the things that had bothered us and to get the game to where we want it to be. Whether we'll actually finish it and release it as a paid title is hard to say, though. All things considered I still consider Broforce to be the better game, and it is closer to release than Murder Island is, so we'll continue working on that for the time being. I do feel we owe it to the Ouya and organisers to at least finish what we'd wanted to do for the prototype, and to have a rounded, more stable version that we can put online would be nice.
I've been meaning to do a post mortem on our Ludum Dare game, Ore Chasm, for a while now, and I thought I might as well do it now before it completely fades from memory.
Background
We are currently working on a game called BroForce for which we need to, at some point, implement networked multiplayer. No one in our team has any experience in implementing multiplayer, so we did a game called Deathsmashers in a for-fun private jam. That turned out pretty well, but with it being a co-op FPS I felt that we didn't really answer many of the questions that we needed answering. It is usually a good idea to have some sort of plan for what you will be doing in a jam, and I requested that we do a fast paced platformer with networking and lots of terrain destruction.
Design
Our lead designer came up with the idea of doing a mining game in the vein (heh) of MotherLoad. This suited what I wanted to try technically very well, and could be worked to incorporate the theme of 'You are the villain' pretty easily - everybody loves mining conglomerates, right? We didn't quite manage to foster the feeling that you are destroying the entire planet as well as we could have, though.
The game's design is focused around a very simple but effective loop: go down, get ore, try to make it back up, upgrade your gear. Keeping the loop focused and simple really worked for us and it turned out to be highly compelling. Subtle changes in the game world as you get deeper, along with one or two things to discover also added a lot to the feeling of progression (besides being able to smash terrain near the surface with the more powerful late game lasers).
The idea for the mining laser as implemented in the game was partly inspired by No Time To Explain's recoil-movement mechanic and works really well in making the weapon feel powerful. I'd initially wanted to make the starting laser much weaker, with limited range and movement capabilities - but wisely we opted for the design as is. Having the initial laser nerfed would have made it less effective at teaching the game's mechanics, besides unnecessarily limiting the player.
Some things we had planned did not make it in: We had planned to have creatures underground as you get deeper (although there may or may not be a mysterious and majestic sandworm in certain builds of the game). A greater variety of weapons and some sort of metagame would also have helped a lot with replayability of the game. Upgrades and scaling are also hard to test when you don't have a lot of time and so the progression and cost of items are not as balanced as they could be. Still, I think we did a good job of balancing in the limited time we had to make the game.
Tech
As usual we used the Unity engine. One of the technical challenges we faced was managing such a large game world with so many game objects - the map is 350x1024 blocks large, with each block being a game object in itself. We handled this by only spawning onscreen blocks, and despawning those that go offscreen and asset pooling them. We used a "lazy mans's asset pooling" system that I wrote earlier which worked very easily and painlessly for us.
We use a standard perlin noise map to generate the map - 4 layers of perlin noise combined with depth determine a block's state. The master client determines a random seed and keeps track of all damaged/destroyed blocks. When a client joins, the seed is sent and the client can generate the exact same map. Afterwards a list of all dirty blocks' state is sent.
Networking
We used the Photon library and cloud hosting for the multiplayer portion of the game. Although I sometimes like to complain about Photon a lot, it is a brilliant library and service and I would recommend it to anyone looking for a quick-and-easy way to get their games networked and hosted on a cloud.
One thing I learnt about networking is that it doesn't necessarily need to be as exact as I'd expected: Player and beam locations are often not the same on different clients, but damage is determined locally and then distributed. Ore isn't synchronised at all! When a block is destroyed, its ore drop is determined locally. It is theoretically possible (but hard) for two players to pick up the same piece of ore. Fortunately the nature of the game is quite suited to this relatively low level of synchronisation.
Visuals
We went for a low-res pixel art style, which (with a talented artist) looks good and works well in the context of a jam. The surface world look was achieved by having some parallax elements on a seperate camera with bloom. Lots of camera shake and a distortion/wobble effects on explosions help with the juiciness of the game and really adds to the feel.
Closing Thoughts
This was quite a successful jam for us, considering that we won 1st place overall in the jam :). Besides that, we had a lot of fun and learnt a fair amount about networking. Unfortunately not all the lessons are highly applicable to Broforce, where the players are far more dependent on each other than in Ore Chasm. It did take a lot of hard work, and we had 3 programmers - doing a networked game isn't really a good idea for a jam unless you have good reason to do so.
I'm trying to develop my blog and skills as a writer - if you have any questions or feel there's some important aspect of the game I neglected - please leave a comment!
So! The jam finished about a week ago, which has given some time for the dust to settle and for us to collect our thoughts. This was a really tough jam, a lot of things went wrong and we didn't quite get where we wanted to with the game, but we still had a blast and made a prototype which I hope shows a lot of promise.
Before I start I should say that all opinions are my own and do not necessarily reflect the views of the rest of our team!
What Went Wrong
In short... a lot!
Ambition
We were ridiculously ambitious for our game. Shortly before this jam we'd done really well in Ludum Dare, winning the "Overall" category in the jam with our game Ore Chasm. 12 days seem like a really long time, we have a good idea for how much we can get done in a weekend's time for a typical jam timespan but the longer time threw us out a bit and we set our sights too high. Doing a 3D game is almost always a terrible idea for a jam, and we wanted a 3D game with different mechanics per level, a strong narrative, unlocks and a metagame, dinosaurs and time travel! Which lead to the next issue...
Spreading ourselves too thin
Working on so many different scenes and mechanics meant we never could give enough attention to any one aspect. In retrospect we should have cut down on story elements, and probably done either only the driving sections or shooting sections, and fleshed out/polished either. We spent a lot of time on content that didn't make it into the game at all. It is common jam advice to work bottom up - make something small and improve on it - but we worked from with a top-down methodology.
The Ouya/Dev environment
As is to be expected from a product in such an early phase of development, we had a number of issues with the ouya itself. The first and most significant being that our Ouya dev kit didn't work out of the box at all! We were lucky to know a nearby developer who also had an Ouya that we could use to test our game on. Still, this meant we had far less time to test our game on-device than optimal. Building the game for Ouya and deploying also took up a fair amount of time - compounded by the fact that I had never built a game for the Android environment. The support given by Ouya staff and resources available on their forums were great though, and we managed without too many troubles.
We also overestimated the power of the device, especially on the video side. Luckily the visual style of our game suits it being run in ridiculously low res (I think in the end we settled for 270p), but even that in addition to a fair amount of optimisation was not enough to stop the framerate from chugging at certain parts of our game. Another reason we should have made a 2D game!
Finally, the Ouya controller is kind of... bad. The ouya devs have since responded and are improving the controls so I trust this won't be an issue on launch - but the large input delay and inaccurate axis readings made that our game doesn't play nearly as nice with an ouya controller as it does with an Xbox controller. In the end we opted for a deadzone of about 0.4! We tried to compensate for the problems by adding in a lot of autoaim, which helps, but does not solve the problem altogether. By carefully watching the youtube videos of other entries it seems evident that other devs were facing the same issues. Again, I don't think these are massive problems for a product in its infancy and the ouya devs are aware so I'm sure these issues will be solved before launch.
Playtesting
As a result of the previously mentioned problems, we did not spend nearly enough time actually just playing our game. The controls aren't as intuitive as they should be, the difficulty is a bit haphazard and there are a fair number of bugs present.
I'm stupid
Yep, I'm stupid. Only a few hours before submission, I accidentally our whole Mercurial repository by committing stuff with the LargeFiles extension, which bitbucket does not support. This meant that the frantic bugfixing which always happens a few hours before submission in a jam could only be done on one machine. If I had more time I could probably have fixed my repo, or worked out a different setup for our mercurial, but there was no time.
What went right
Concept
I think our concept for the game - having lots of different, semi-repeating scenes getting weirder and more difficult a-la Amazing Wagon Adventure is really strong and if fully realised would have made for a really fun, whacky, replayable and unique experience, while allowing us to do pretty much what we want gameplay wise. Doing something more narrative driven was also a nice change for us, and we learnt some valuable lessons there.
Aesthetics
As per usual our (one man) art team did a kickass job and produced more content than we could even use. I really like the visual style of the game. On top of that we had some cool terrain tech that allows us to have rippling terrain and marks on ground, making the game quite 'juicy'.
Mood
Even though it does not come across nearly as strongly as I hoped, I still think we somewhat succeeded at establishing the mood we intended - of survivors on an island encountering increasingly weird scenarios. We did have a whole story planned out - which would have explained what exactly is going on on the island and tied everything together - but we didn't have time to implement it all. I think the story screen also works quite well - although the writing itself didn't have time to be iterated upon, and I'm not a particularly good writer.
Gameplay
Although again not nearly where we wanted it to be - I think the game sections are quite fun. Shooting could certainly have been improved by a lot, but there are a lot of different ways of playing the game, and killing mooks by throwing guns at them is quite fun.
Vehicle section
The vehicle section is probably the strongest part of the game - everybody seems to have liked our laser-breathing T-Rex. It's also a lot of fun to play with a friend, and can be quite chaotic (in a good way!).
Final Thoughts
So, our jam didn't go nearly as well as I'd hoped, and I'm not quite sure of our chances of winning. But still think we have an outside chance, and I think at least our trailer is one of the better ones. Despite this we learnt a lot in this jam and still had a good time, and we might take the game further if we get a good response. Doing an extended jam (with prizes!) was a great change and I hope there are more of these in the future - we'd definitely like to compete again. It was great being part of something new and exciting and I'm looking forward to the future of the Ouya.
More progress! Little over 48 hours left to go in the jam, and things are starting to come together. We have enough sections for there to be a feeling of progression, and although we've encountered a few technical limitations we've managed to find workarounds for most of them so that our game plays nice and smooth on the Ouya. We've also come up with a tentative title for our game: Strange happenings on Murder Isle. It might still change last moment but for now I think it suits the game perfectly. Due to the intense development we've not had as much time to test gameplay as I would have liked but it I do think the game is quite fun and should lend itself really well to some coop chaos.
Here is a photo of the team, hard at work:
And here is a screenshot of our intrepid hero coming tantalisingly close to unraveling the mystery of Murder Isle:
Why is this high tech facility built inside an active volcano on a seemingly deserted island? What the hell is wrong with the warthogs? Why are the mysterious gunmen so intent on murdering innocent castaways? Why is nothing as it seems and most bafflingly, where the hell did the T-Rex come from? Strange happenings indeed...